ESTUDIOS FILOLÓGICOS
41: 235-249, 2006
DOI: 10.4067/S0071-17132006004100014
Variabilidad idiofónica en español como herramienta forense*
Idiophonic variability in Spanish as a forensic tool
Claudia Rosas1, Jorge Sommerhoff2
1
Universidad Austral de Chile, Facultad de Filosofía y Humanidades,
Instituto de Lingüística y Literatura, Valdivia, Chile. e-mail:
claudiarosas@uach.cl.
2
Universidad Austral de Chile, Facultad de Ciencias de la Ingeniería.
Instituto de Acústica, Valdivia, Chile.
* Etapa inicial del proyecto de investigación
DID UACh S-2005-72 financiado por la Universidad Austral de Chile. Parte de
este trabajo fue presentado en el XVI Congreso de la Sociedad Chilena de
Lingüística SOCHIL, celebrado en Valdivia los días 2,
3 y 4 de noviembre de 2005.
Este trabajo presenta aspectos metodológicos de una investigación en curso y resultados parciales correspondientes a una parte del corpus experimental obtenido de las grabaciones de frases en ambiente seco y reverberante de tres informantes valdivianas. El campo reverberante modificó las características de la voz analizada. De acuerdo a los indicadores acústicos seleccionados, las principales diferencias se observan en el historial de los formantes comparados: F1, F2, F3 y F4, aunque con variaciones en la altura, intensidad y longitud de las zonas espectrales. La menor diferencia se ubica en el rango de la F0.
Palabras clave: identificación, hablante, forense.
In this paper we present some methodological aspects and preliminary results of an investigation in progress dealing with a section of the experimental corpus obtained from sentences read by three valdivian informants in both an echoless and an reverberant environment. The reverberant field modified the characteristics of the voice analyzed. In accordance with the acoustic selected indicators the main differences were in the history of the compared formants: F1, F2, F3 and F4 with some variations in frequency, intensity and length in the spectral zone. The smallest difference was observed in the F0 rang.
Key words: identification, speaker, forensic.
I. INTRODUCCIÓN
La fonética tiene diversas aplicaciones que se relacionan con diferentes ámbitos donde está implicado lo oral. Además del ámbito natural y prioritario de la enseñanza de primeras y segundas lenguas (Rosas 2005), existen otros ámbitos de interés social como la medicina (enfermedades del habla); la ingeniería (síntesis y reconocimiento del habla); y el forense (esclarecimiento de hechos).
Es evidente que existen diferencias fonéticas entre hablantes (dialectales). Estudios que abordan estos aspectos son los que más abundan. En este sentido se encuentran, además de los estudios puramente acústicos, otros de corte sociolingüístico que intentan descubrir una relación entre variables físicas (sexo, edad, constitución física) y características acústicas (Van Dommelen 1995), incluso con hábitos sociales como los de un fumador (Braun y Rietveld 1995), además de otras psicosomáticas (Van Rie y Beezooijen 1995). Pero la variabilidad es un hecho que no sólo está presente entre hablantes, sino también en un mismo hablante, y el grado de variabilidad que este hecho supone no siempre es menor que el producido entre hablantes diferentes (Baldwin y French 1990).
En ocasiones, algunas de estas variaciones sumadas a otras derivadas de las condiciones cuantitativas y cualitativas (tamaño de la muestra y tipo de registro) de la grabación han llevado a más de algún experto a señalar que no es posible reconocer la voz de una persona con 100% de certeza (Ladefoged 2003). En este sentido, Robertson et al. (1995), Broeders (1995) y Nolan (1995) que comparten esa opinión, han abordado el problema en términos probabilísticos, estableciendo categorías en una escala que va desde "altamente probable", "probable", "posible" hasta "improbable". Además de la prudencia de las afirmaciones, otros autores han enfatizado la rigurosidad en los métodos e instrumentos utilizados (Homayounpour y Chollet 1995). Sin embargo, es útil también recordar que tratándose de un fenómeno comunicativo existen otras perspectivas de análisis además de la acústica, paralelas o complementarias: perceptiva (Pollack et al. 1954; Compton 1963; Stevens et al. 1968; Hollien et al. 1982; Kuwabara y Takagi 1991; Kreiman y Papkun 1991; Pisoni 1993); y perceptiva y acústica (De Figueredo y Olivier 1995).
Dificultades como las descritas también se han comprobado en el ámbito forense nacional (Sommerhoff y Rosas 2003a, 2003b y 2004).
Dentro de la gran gama de factores que pueden contribuir a la intravariabilidad del hablante _escasamente tratada_ hay un aspecto que no ha sido explorado y que tiene que ver con cuánto y cómo pueden variar las características acústicas de la voz en diferentes condiciones ambientales.
Estos han sido los antecedentes que se han tenido en cuenta y que han motivado la formulación de un proyecto en esta línea.
La hipótesis que se establece como base de la investigación en curso es que la variabilidad acústica ambiental de la voz es un hecho que se puede reconocer, representar y jerarquizar. La presente investigación se propone los siguientes objetivos generales: (1) estudiar la variabilidad ambiental fonético-acústica idiolectal del español en Valdivia, con el objeto de caracterizar la variabilidad ambiental fonética-acústica idiolectal en español; (2) contribuir al conocimiento de los especialistas de fonética y acústica con el fin de mejorar las aplicaciones en el ámbito forense; y finalmente, (3) incentivar y potenciar las actividades de investigación interdisciplinaria de la Fonética y Acústica. Los objetivos específicos son: 1) describir las propiedades fonético-acústicas segmentales y suprasegmentales idiofónicas en la variedad valdiviana chilena del español; y 2) jerarquizar la variabilidad fonético-acústica de los parámetros segmentales y suprasegmentales idiofónicos seleccionados en la variedad valdiviana chilena del español.
De acuerdo con la problemática planteada y con los objetivos que se persiguen se aplicará a la señal de voz un enfoque acústico que contempla medir y analizar los siguientes indicadores, aceptados por los especialistas (Stevens 1971; Battaner et al., 2004): valor medio de la F0, forma de la onda, valor medio de los formantes vocálicos, análisis del F3, sonido alveolar fricativo sordo [s], y sonidos nasales [n] y [m].
Nuestra investigación contempla básicamente tres etapas, a saber: (I) constitución del corpus, (II) análisis acústico, y (III) interpretación de los resultados (caracterización y jerarquización de la variabilidad de las muestras).
En esta oportunidad, se presenta la metodología seguida para la obtención y tratamiento del corpus, y se comenta algunos resultados procedentes de tres informantes valdivianas.
II. METODOLOGÍA
1. CONTRUCCIÓN DEL CORPUS
Para definir el corpus se elaboró un diseño general consistente en tres etapas: (1) elaboración del texto; (2) selección de los informantes; y (3) grabaciones.
1.1. Elaboración del texto
a) Características del texto
Esta etapa persigue la finalidad de elaborar 30 frases según parámetros vocálicos, consonánticos y acentuales. Las frases deben contener vocales tónicas y átonas precedidas de consonante oclusiva sorda o /s/ y seguidas de consonante oclusiva sorda o /s/; vocales tónicas y átonas precedidas de consonante nasal /n/ o /m/ y seguidas de consonante nasal /n/ o /m/.
b) El etiquetado de las frases
A cada frase, de acuerdo a su estructura, se le asigna una clasificación que permitirá el etiquetado posterior de los elementos muestrales a analizar. Los ficheros están compuestos por un dígito inicial, tres letras y un dígito final. El primer dígito corresponde a la variable acentual: usaremos "1" para referirnos a las vocales tónicas y, "2" para las átonas. Las letras representan fonéticamente los segmentos consonánticos y vocálicos considerados, que coinciden con la estructura silábica CV$C; por ejemplo: kas, representa una sílaba formada por una consonante velar oclusiva sorda "k" y una vocal central "a", seguida de una consonante alveolar fricativa "s". El dígito final corresponde a la variable ambiental de grabación. Sólo especificaremos las salas reverberantes1.
c) Frases elaboradas
1. Tónicas /a / y / e/ precedidas de /p/, / t/, /k/, y seguidas de /s/
1. El paso
está cerrado 1pas
2. La taza
tiene café 1tas
3. La casa
está en un cerro 1kas
4. La guagua
tiene sobrepeso 1pes
5. María
dio un bostezo 1tes
6. El queso
es nutritivo 1kes
2. Átonas /a / y / e/ precedidas de /p/, / t/, /k/, y seguidas de /s/
7. El pasillo
está resbaloso 2pas
8. La tacita
tiene té 2tas
9. La casita
está cerrada 2kas
10. La pecera
tiene agua 2pes
11. María
terminó la tesina 2tes
12. El quesito
es nutritivo 2kes
3. Tónica /a/ precedida de /s/ y seguida de /p/, /k/
13. En el charco
hay un sapo 1sap
14. El saco
tiene frutas 1sak
4. Tónica /e/ precedida de /s/ y seguida de /t/
15. María dibuja una zeta 1set
5. Átona /a/ precedida de /s/ y seguida de /p/, /k/
16. El zapallo
está verde 2sap
17. El saquito
tiene avellanas 2sak
6. Átona /e/ precedida de /s/ y seguida de /t/
18. El macetero tiene una planta 2set
7. Tónica /a/ precedida de nasal /n/ y seguida de consonante nasal /n/
19. La nana pasea a la guagua 1nan
8. Tónica /e/ precedida de nasal /n/ y seguida de consonante nasal /n/
20. La nena tiene miedo 1nen
9. Átona /a/ precedida de nasal /n/ y seguida de consonante nasal /n/
21. La nanita pasea a la guagua 2nan
10. Átona /e/ precedida de nasal /n/ y seguida de consonante nasal /n/
22. La nenita tiene hambre 2nen
11. Tónica /a/ precedida y seguida de /p/, /t/
23. Pedro compra
papas 1pap
24. El tata
juega con el niño 1tat
12.Tónica /e/ precedida y seguida de /k/ y /s/
25. La abuela prepara
un queque 1kek
26. La lluvia
no cesa 1ses
13. Átona /a/ precedida y seguida de /t/, y /s/
27. Tatiana
escribe una carta 2tat
28. María
sazona la comida 2sas
14. Átona /e/ precedida y seguida de /p/, /t/
29. Esos pepinos
están verdes 2pep
30. La tetera
está hirviendo 2tet
b) Frases desordenadas (las utilizadas para las grabaciones)
1. El paso
está cerrado 1pas
2. La tetera
está hirviendo 2tet
3. El queso
es nutritivo 1kes
4. La taza
tiene café 1tas
5. María
sazona la comida 2sas
6. Esos pepinos
están verdes 2pep
7. La guagua
tiene sobrepeso 1pes
8. Tatiana
escribe una carta 2tat
9. María
dibuja una zeta 1set
10. La abuela
prepara un queque 1kek
11. María
dio un bostezo 1tes
12. El saquito
tiene avellanas 2sak
13. La lluvia
no cesa 1ses
14. La nanita
pasea a la guagua 2nan
15. El pasillo
está resbaloso 2pas
16. La casa
está en un cerro 1kas
17. El tata
juega con el niño 1tat
18. El zapallo
está verde 2sap
19. La tacita
tiene té 2tas
20. Pedro
compra papas 1pap
21. La pecera
tiene agua 2pes
22. La nenita
tiene hambre 2nen
23. El saco
tiene frutas 1sak
24. La casita
está cerrada 2kas
25. María
terminó la tesina 2tes
26. La nena
tiene miedo 1nen
27. El quesito
es nutritivo 2kes
28. La nana
pasea a la guagua 1na
29. En el
charco hay un sapo 1sap
30. El macetero
tiene una planta 2set
1.2. Selección de los informantes. Se procuró que las características sociales de tipo sexual, etaria, geográfica, cultural y articulatoria de los locutores informantes fuesen coincidentes, con el propósito de aislar la variable fonética que interesaba investigar. Para los rasgos referidos a sexo, edad, geográfico y cultural se establecieron los siguientes criterios de selección: mujeres de entre 20 y 25 años, de procedencia valdiviana, con estudios universitarios. En cuanto al rasgo articulatorio, se aplicó un examen auditivo y visual, con el fin de comprobar "a oído" las voces, además de observar la dentadura, fundamentalmente para descartar alguna anomalía fisiológica (fonatoria).
De acuerdo con lo anterior, para la elaboración del corpus general de la investigación se seleccionaron 3 mujeres, valdivianas, de 20 años, universitarias, sin observaciones articulatorias de interés.
1.3. Las grabaciones. Para realizar las grabaciones se consideraron dos aspectos: lectura y diseño acústico, cuyos procedimientos se describen a continuación:
a) La lectura
Para la tarea de lectura se aplicó la siguiente pauta:
1) Antes de realizar
la grabación, se pidió a cada locutora que leyera el texto completo
para familiarizarse con las frases y asegurar la fluidez.
2) Luego,
se pidió a cada locutora que leyera el corpus para ser grabado.
3) Al terminar
la tarea, en el caso de haberse detectado errores en alguna(s) de la(s) frase(s)
leída(s), se realizó una segunda grabación.
b) Diseño acústico
El estudio requiere una comparación de voces idénticas emitidas en ambientes acústicos distintos. Para ello se efectuó una grabación inicial, posteriormente manipulada para ser reproducida idénticamente en cualquier ambiente. Los ambientes elegidos difieren en la relación existente entre la densidad de energía directa y la densidad de energía reverberante. Como se sabe, esta relación cambia con la distancia existente entre el locutor y el auditor; a medida que la distancia aumenta, la relación entre la densidad de energía directa y la densidad de energía reverberante disminuye. La primera grabación se llevó a cabo en una sala anecoica; es decir, un tipo de sala cuyas superficies límites no reflejan sonido. Estas salas simulan un recinto abierto y, por ende, la relación entre la densidad de energía directa y la densidad de energía reverberante es infinita, ya que ellas se caracterizan por tener una densidad de energía reverberante igual 0 watt/m3. La segunda grabación corresponde a las voces grabadas en la sala anecoica a la cual se le agregó, con una estación digital Tascam SX-1, un campo reverberante equivalente a 5 veces la distancia crítica, que equivale a un lugar en la sala donde la relación entre la densidad de energía directa y la densidad de energía reverberante es 0,2.
En resumen, definidas las salas, contactadas las informantes, y dado a conocer el propósito general de la investigación, se procedió a realizar la grabación en la sala anecoica, a partir de cuyo corpus se efectuó la reproducción en distintos ambientes de reverberación, de acuerdo a los procedimientos indicados.
III. ANÁLISIS ACÚSTICO DE LAS MUESTRAS
Nuestro corpus se limita a las frases del corpus experimental general de las tres informantes utilizadas. Las muestras consideradas están integradas por vocales tónicas /a / y / e/ precedidas de /p/, /t/, /k/, y seguidas de /s/, y frases integradas por vocales tónicas /a/ y /e/ precedidas y seguidas por nasal /n/. En cada una de los contextos seleccionados se midieron los siguientes indicadores acústicos: F0, valor medio de los formantes vocálicos (F1, F2, F3 y F4); y ancho de banda de los formantes vocálicos. Así analizamos 48 archivos y efectuamos 672 mediciones. Para el análisis se utilizó el programa Multi-Speech Modelo 3700, de la casa Kay Elemetrics Corp. que permite trabajar con todos los parámetros acústicos mencionados mediante la visualización, manipulación y etiquetado de los elementos segmentales y suprasegmentales (oscilogramas, espectrogramas, estructuras espectrales de segmentos, curvas melódicas y curvas de intensidad), además de proporcionar por cada gráfico resultados numéricos y estadísticos.
IV. RESULTADOS
Para medir los indicadores acústicos fue necesario identificar las vocales, separándolas de sus contextos consonánticos. Para ello se realizó una segmentación del material muestral a analizar, junto con la creación de los archivos correspondientes.
La totalidad de las figuras presentadas constituye una muestra, si bien traduce la generalidad de los datos observados, 48 frases de un total de 180, lo que representa un 26,6%.
a) Segmentación vocálica
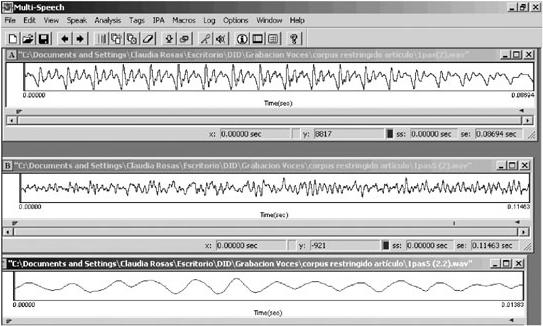
El oscilograma sirvió para hacer la segmentación de las vocales. En el caso de las reverberantes se prestó especial atención a la parte del segmento que permitía observar la menor irregularidad.
La figuras 1 muestra un ejemplo de los oscilogramas de la vocal tónica /a/ precedida de /p/ y seguida de /s/, anecoica y reverberante y su correspondiente segmentación. Nótese la regularidad de la anecoica frente a la irregularidad de la reverberante. El hecho de que en las reverberantes no se aprecie a primera vista un patrón que se repita de manera aproximada puede llevar erróneamente a confundirlas con una señal de ruido.
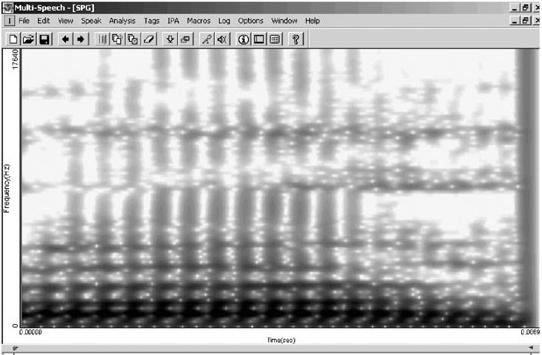
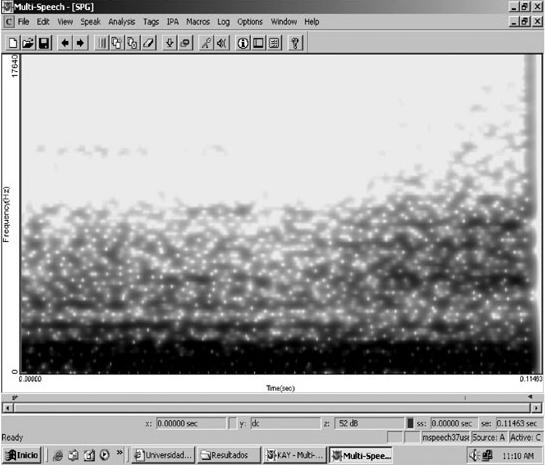
En las Figuras 2a. y 2b. presentadas a continuación se presentan los espectrogramas de la modalidad vocal tónica /a/ precedida de /p/ y seguida de /s/ en ambiente seco y reverberante para que se aprecie la definición de los armónicos y la simetría de los pulsos glotales en la primera frente a la asimetría de los mismos en la segunda, donde éstos aparecen cubriendo a distintas frecuencias distintas gamas de amplitudes. No obstante las diferencias comentadas, es posible distinguir una banda oscura en el eje horizontal de la modalidad reverberante que representa la sonoridad
|
 |
 |
b)
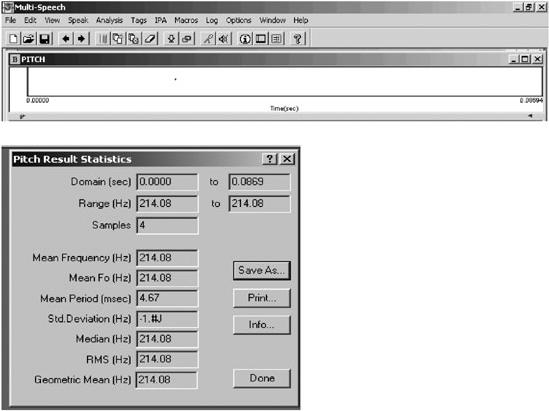
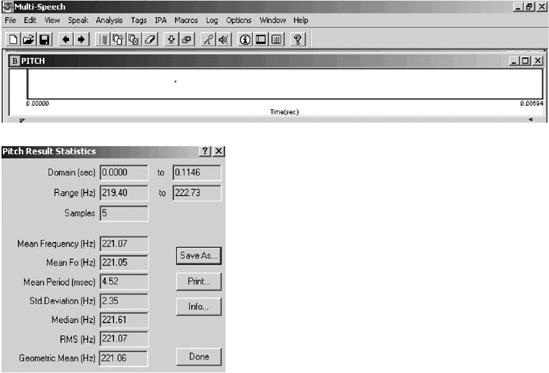
La frecuencia del fundamental
No hemos observado diferencias significativas en los rangos de F0 entre las
variantes analizadas, como puede apreciarse en las figuras
3a. y 3b que registran valores muy similares: 214.08
Hz y 221.05 Hz, correspondientes a las variantes anecoica y reverberante de
la modalidad vocal tónica /a/ precedida de /p/ y seguida de /s/, respectivamente.
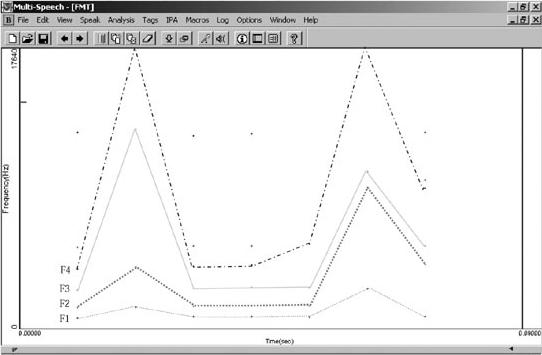
c) Los formantes: valor central, ancho de banda e intensidad
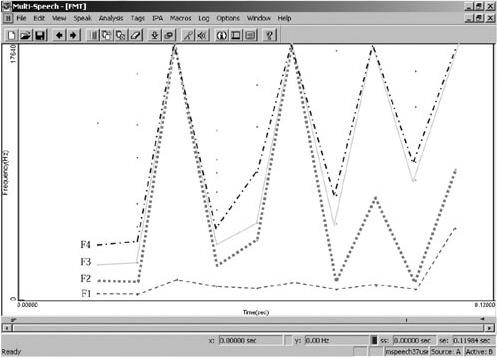
Los formantes presentan variaciones en el eje temporal, en cuanto a frecuencia, ancho de banda e intensidad. Aunque intuimos regularidad en las diferencias encontradas, los datos no nos permiten concluir nada todavía. Una segunda etapa tendrá que ver con la explicación de estas variaciones, como asimismo, con una sistematización de las mismas.
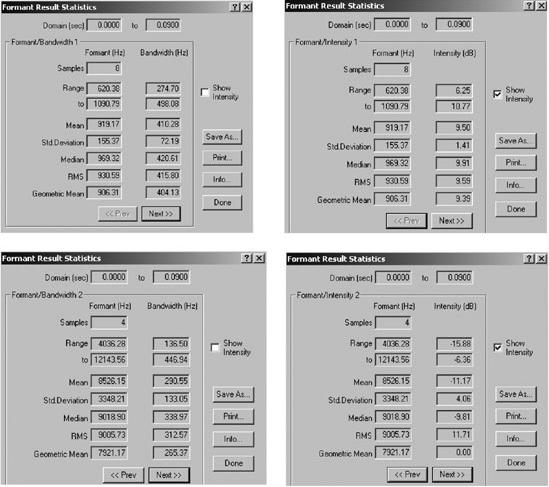
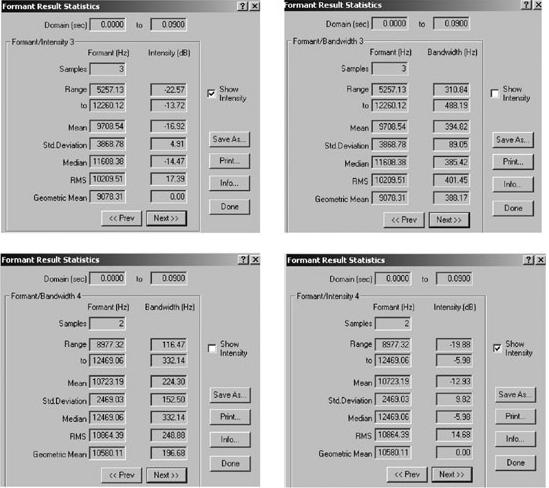
Las Figuras 4a. y 4b. presentan un ejemplo del comportamiento de cada uno los 4 primeros formantes analizados, anecoica y reverberante. Ambos gráficos se acompañan de las tablas que muestran los datos estadísticos referidos al ancho de banda e intensidad, proporcionados por el programa.
 |
 |
 |
Tablas
referidas al ancho de banda e intensidad correspondientes a la modalidad
anecoica. |
  |
 |
Tablas
referidas al ancho de banda e intensidad correspondientes a la modalidad
reverberante. |
  |
V. CONCLUSIÓN
Los resultados, que representan un 26.6% del total analizado hasta ahora, nos permiten evidenciar, en todos los casos, que el campo reverberante modificó las características de la voz analizada: alteraciones en la frecuencia, intensidad y ancho de banda de los formantes (F1, F2, F3 y F4) comparados y, en menor medida, de la fundamental, que más y nuevos análisis _que aún restan_ habrán de precisar. Etapas posteriores al análisis de la totalidad del corpus permitirán caracterizar y jerarquizar las diferencias, como asimismo evaluar su contribución en la aplicación de la práctica forense.
NOTA
1 Para etiquetar los distintos grados de variabilidad ambiental hemos iniciado la numeración en "5" a fin de permitir la inserción relativa de otros grados de reverberación.
OBRAS CITADAS
Baldwin, J., P. French. 1990. Forensic Phonetics. Londres: Printer Publisheds Limited.
Battaner, E. et al. 2004. "Vile: Estudio acústico de la variación inter e intralocutor en español", en 6ª Congreso de Lingüística General. Santiago de Compostela, 3-7 de mayo de 2004. Área de Lingüística Xeral, Universidade de Santiago de Compostela.
Braun, A., T. Rietveld. 1995. "The influence oF Smoking Habits on Perceived Age". ICPhS 95 (2): 294-297.
Broeders, A.P.A 1995. "The role of Automatic Speaker Recognition Techniques in Forensic Investigation". ICPhS 95 (3): 154-163.
Compton, A. J. 1963. "Effects of filtering and vocal duration upon the identification of speakers aurally". Journal of the Acoustical Society of America. 35: 1748-1752.
De Figuereido, R. M., S. L. Olivier. 1995. "Speaker Identification Using a Spectral Moments Metric with the Voiceless Fricative /s/". ICPhS 95 (3): 286-289.
Hollien, H., Majewski W., E. T. Doherty. 1982. "Perceptual identification of voice under normal, stress and disguise speaking conditions". Journal of Phonetics. 10: 139-148.
Homayounpour, M.M., G. Chollet. 1995. "A Study of Intra _and iInter- Speaker Variability in Voices of Twins for Speaker Verification". ICPhS 95 (3): 289-301.
Kreiman, J., G. Papcun. 1991. "Comparing discrimination and recognition of unifamiliar voices". Speech Comunication 10: 265-275.
Kuwabara, H., T. Takagi. 1991. "Acoustic parameters of voice individuality and voice-quality control by analysis-syntesis method". Speech Comunication 10: 491-495.
Ladefoged, P. 2003. Validity of voice identification. Journal of the Acoustical Society of America. Vol. 114 (4) Pt.2.
Nolan, F. 1995. "Can the definition of each speaker by expected to come from the laboratory in the next decades?". ICPhS 95 (3): 130-137.
Pisoni, D. B. 1993. "Long-term spectral memory in speech perception: some new findings on talker variability, speaking rate and perceptual learning". Speech Comunication 13: 109-125.
Pollack, I., Pickett J.M. y W. Sumby. 1954. "On the identification of speakers by voice". Journal of the Acoustical Society of America 35: 354-358.
Rosas A., C. 2005. "La fonética en la Universidad Austral de Chile: revista general". Documentos Lingüísticos y Literarios 28: 86-88.
Sommerhoff, J. 2003. "Aplicación de la medida de disimilitud de Itakura a la medición de la inteligilibilidad de la palabra". Proyecto de Investigación DID S-2003-58. Instituto de Acústica. Universidad Austral de Chile.
Sommerhoff J., C. Rosas. 2003. Informe pericial Defensoría Penal Pública de Caldera y Chañaral.
Sommerhoff J., C. Rosas. 2003. Informe pericial Defensoría Penal Pública La Serena.
Sommerhoff J., C. Rosas. 2004. Informe pericial Defensoría Penal Pública La Serena.
Sommerhoff J., C. Rosas. 2004. Informe pericial Defensoría Penal Pública Coronel _ Lota.
Stevens, K. 1971. "Sources of Inter.- and intra-speaker variability in the acoustic properties of speech sounds". Proceedings of the Seventh International Congress of Phonetic Sciences. Ed. por R. Charboneau y A. Rigault. The Hague: Mouton: 206-232.
Stevens, K. et al. 1968. "Speaker identification and authentication: a comparison of spectrographic and auditory presentation of speechmaterials". Journal of the Acoustical Society of America 44: 1596-1607.
Tosi, O. et al. 1972. "Experiment on voice identification". Journal of the Acoustical Society of America 51: 2030-2043.
Van Dommelen, W. 1995. "Speaker and Listener sex for speaker height and weight identification". ICPhS 95 (3): 738-741.
Van Rie, J., R. Bezooijen. 1995. "Perceptual characteristics of voice quality in dutch males and females from 9 to years". ICPhS 95 (3): 290-293.