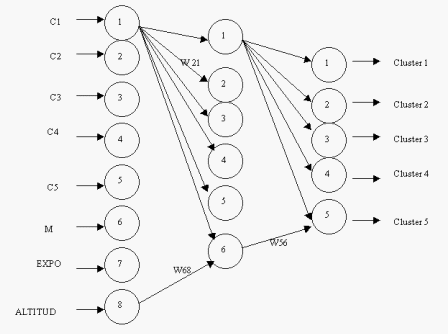
Fig. 1. Arquitectura
general de la red.
C. J. Ruiz Tagle et al. Síntesis
Tecnológica. N° 1 (2004) 19-23
DOI:10.4206/sint.tecnol.2004.n1-04
APLICACIÓN DE DATA MINING SOBRE UN SIG DE CARACTERIZACIÓN FORESTAL
CAMILO JOSÉ
RUIZ-TAGLE MOLINA
MARTÍN SOLAR MONSALVES
Universidad Austral de
Chile, Ingeniero Civil en Informática, cruiztagle@inf.uach.cl,
Casilla 567- Valdivia.
Universidad Austral de Chile, Ingeniero Civil Industrial, MBA, msolar@uach.cl,
Casilla 567- Valdivia.
Resumen
La Minería de datos corresponde a la aplicación de algoritmos para encontrar patrones de comportamiento ocultos en los datos. La técnica será aplicada sobre un conjunto de bases de datos de un SIG que caracteriza el nivel de vulnerabilidad ambiental del suelo de la comuna de Lanco, provincia de Valdivia, Chile. Con ella se pretenderá asignar el nivel de vulnerabilidad ambiental a porciones de terreno o píxeles que carecen de mediciones directas de terreno.
Palabras claves: análisis avanzado de datos, Data Mining, GIS, Redes Neuronales.
Summary
Data mining corresponds to the application of algorithms to find hidden behavior patterns in the data. The technique will be applied on a set of data bases of a SIG that characterizes the level of environmental vulnerability of the ground of the commune of Lanco, province of Valdivia, Chile, seat Los Lagos. With this technique it will be tried to assign the level of environmental vulnerability to portions of land or pixels that lack direct land measurements.
Keywords: advanced analysis of data, data Mining. GIS, Neural Networks.
1. INTRODUCCIÓN.
El instituto Forestal, INFOR, dentro del contexto del proyecto Desarrollo y aplicación de alternativas de manejo para el abastecimiento continuo de bienes y servicios con bosques nativos, se encuentra con la problemática del desarrollo del índice de Vulnerabilidad ambiental. La importancia de este último es que permite evaluar la propensión al deterioro de los ecosistemas. La información obtenida con este permite tomar decisiones para realizar actividades de manejo sustentable.
El índice de vulnerabilidad de Suelo-agua dice relación con las variables que afectan al suelo y que son causantes del aporte de sedimentos a los cursos de agua, procesos erosivos y aquellos factores que condicionan las actividades de manejo y cosecha en el sitio [1].
2. SITUACIÓN DE LOS DATOS DE ESTUDIO.
La tabla frag_suelo contiene información de las variables auxiliares asociadas a 217 píxeles (o registros) contenidos en un SIG (Sistema De Información Geográfico). Entre estas variables se cuenta con:
• idd: identificador de registro que representa al conglomerado y la parcela de un punto dado. Ejemplo: idd=112, conglomerado=11, parcela=2.
•
C1: banda 1 Landsat 7 ETM+
•
C2: banda 2 Landsat 7 ETM+
•
C3: banda 3 Landsat 7 ETM+
•
C4: banda 4 Landsat 7 ETM+
•
C5: banda 5 Landsat 7 ETM+
•
m: pendiente del terreno en grados asociado a cada píxel
•
expo: exposición en grados por píxel.
•
Altitud: altitud sobre el nivel del mar en metros.
•
Cluster: cluster de grado de vulnerabilidad.
En esta última variable podemos distinguir diversos niveles que representan grados de vulnerabilidad distintos. Existen 5 niveles de vulnerabilidad. Cuando toma el valor 5, se representan sectores sin problemas evidentes de erosión. Por el contrario, el valor 1 representa Erosión evidente del suelo, presencia de cárcavas y/o zanjas, altas pendientes y es caracterizado por una fuerte exposición a las lluvias dominantes.
Una vez caracterizada la naturaleza de la información presente en los datos de estudio, podemos distinguir en dos grandes grupos la información desde el punto de vista del problema en estudio:
1 Información contenida en la tabla frag_suelo, con asignación de niveles de vulnerabilidad conocidos (variables idd, c1,c2,c3,c4, c5, altitud, m, exposición y cluster conocidos), correspondiente a 217 píxeles.
2 Información que representa los píxeles donde solamente se tiene las variables explicatorias conocidas (idd, c1,c2,c3,c4,c5,altitud, m y expo),donde no se cuenta con datos de terreno que permitan calcular el índice de vulnerabilidad ambiental de suelo-agua y su cluster asociado. esta información se encuentra contenida en la tabla auxil.
3. KDD Y DATA MINING.
Se entiende por data mining a la etapa de extracción de patrones de comportamiento no trivial de los datos, que forma parte del proceso global conocido como descubrimiento de conocimiento en base de datos (kdd: knowledge discovery in databases) [2], [3]. Data mining comprende la utilización de diversos algoritmos provenientes del mundo de las redes neuronales, lógica difusa y árboles de decisión. Dependiendo de la naturaleza del problema, será más adecuada la elección de un tipo de algoritmo y modelo por sobre otro. En este trabajo se diseño un modelo de red neuronal basado en la arquitectura Multilayer Perceptrón que hace uso del algoritmo de aprendizaje Backpropagation, para llevar a cabo la asignación de niveles de vulnerabilidad a píxeles que carecen de mediciones directas en terreno.
4. ASIGNACIÓN DE NIVELES DE VULNERABILIDAD USANDO REDES NEURONALES.
Se confeccionaron 7 experimentos de redes neuronales que se diferencian entre sí en la configuración de parámetros de arquitectura y de aprendizaje. Cada uno de estos experimentos se subdividió en dos experimentos:
•
Entrenamiento y test con los mismos datos (registros): redes MLP1_1, MLP2_2,..,
MLP7_7.
• Entrenamiento y test con
datos distintos (registros): redes MLP1, MLP2,.., MLP7.
Se eligió la mejor red de acuerdo a su calidad de clasificación (matriz de confusión) y su calidad de aprendizaje (curva de aprendizaje).
La figura 1 ilustra la arquitectura general de cada uno de estos experimentos basados en redes multilayer perceptrón:
5. PROCESO DE UTILIZACIÓN DE LA RED.
La utilización de redes neuronales en tareas de clasificación involucra tres etapas claramente diferenciadas [4]:
Entrenamiento: En esta fase son presentados a la red una colección de registros (datos) compuestos de atributos de entrada (variables que permitirán caracterizar una clase de salida) y su respectiva salida (pertenencia del registro a una clase determinada). Con la presentación sucesiva de ejemplos, la red comenzará su proceso de aprendizaje que consiste en el ajuste de los pesos neuronales, minimizando el error (diferencia entre la salida obtenida y la salida deseada, o pertenencia a una clase). La forma como se ajustan los pesos está determinada por la configuración de los parámetros de la arquitectura de la red y por el algoritmo de aprendizaje.
|
Fig. 1. Arquitectura
general de la red. |
Test: Presentación de ejemplos con la pertenencia a una clase conocidos. La red clasifica dichos ejemplos, pero no considera la pertenencia de éstos a una clase. Esta información (salida deseada), es contrastada con la salida obtenida. Con la relación entre la salida obtenida y la deseada, se construye una matriz de confusión. Esta matriz de confusión permite caracterizar la calidad de la clasificación hecha por la red, basándose en la salida obtenida (pertenencia de un registro a una determinada clase), y en la pertenencia real de un registro a una clase.
Recall: una vez entrenada la red (Entrenamiento) y conocida su capacidad de clasificación (Test) se procede a utilizar la red para clasificar conjunto de registros. El objetivo es asignar una clase de salida a cada uno de éstos. Se considera que la calidad de clasificación de la red de los nuevos datos, es como la calidad alcanzada durante la fase de test.
Considerando lo anterior, los datos utilizados para cada una de las fases provienen de dos grupos, como se ilustra en la figura 2.
Dependiendo del grupo de redes estos datos fueron distribuidos de dos formas distintas. Las redes que se entrenan y testean con poblaciones distintas utilizan dos subconjuntos de FRAG_SUELO. Específicamente se utilizó el 75% de los individuos para la fase de entrenamiento y el 25% restante para la fase de test. Se considero especialmente que ambas muestras reflejen las proporciones de presencia de los individuos por clase que se refleja en FRAG_SUELO. La consecuencia directa de esto, es que la calidad de clasificación será mayor en las clases que sean dominantes (mayor número de individuos de una clase sobre otra) en los datos considerados para entrenamiento y test. Por el contrario, las redes que se entrenan y testean con poblaciones iguales utilizan exactamente los mismos datos (la totalidad de FRAG_SUELO) como entrada para ambas fases. Esto naturalmente representara un mayor éxito en la fase de testeo. Sin embargo, es interesante notar el efecto que provoca sobre la red la elección de un enfoque sobre otro.
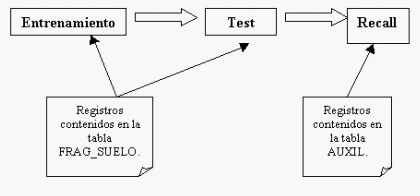 |
Fig. 2. Utilización
de los datos en las fases de aprendizaje. |
Elección de la mejor solución.
La elección de la mejor solución puede ser vista de dos formas diferentes:
i) La mejor solución es aquella donde la calidad de la clasificación, dada por la matriz de confusión es mejor. Tiene incidencia directa sobre esto la situación de los datos (calidad de la muestra, mayor dominancia de una clase sobre otra, etc.).
ii) La mejor solución es aquella dada por la red que demostró una mayor calidad en el aprendizaje. Esta calidad esta condicionada naturalmente por los datos empleados en el entrenamiento y test, pero aquí intervienen la correcta configuración de los parámetros de aprendizaje, los cuales tienen un impacto directo sobre el algoritmo de aprendizaje (Backpropagation), puesto que ellos representan las variables involucradas en la formulación matemática del algoritmo.
En realidad la mejor solución es aquella que representa el mejor desempeño en ambos sentidos.
En la tabla 1 se compara el desempeño en las clasificaciones de ambos grupos de redes.
Como se logra apreciar en ambas tablas, la mejor red corresponde a MLP7 y (MLP7_7) y esta fue la que representó una parametrización más adecuada, dada la situación de los datos y la naturaleza del problema. No es tema de esta publicación exponer las relaciones que ocurren entre los parámetros que intervienen en la configuración de una red neuronal como sucede con la tasa de aprendizaje, momentum, weigth decay y condiciones de poda, por nombrar algunos. Por el momento consideremos que es una buena práctica experimentar con diversas configuraciones e ir observando la curva de aprendizaje de las redes para poder hablar de una configuración paramétrica más adecuada sobre otra. La literatura hace referencia al efecto que tiene la configuración de un parámetro sobre el aprendizaje, pero se sabe muy poco sobre correctas configuraciones colectivas de los parámetros [5].
MLP1 |
MLP2 |
MLP3 |
MLP4 |
MLP5 |
MLP6 |
MLP7 |
|
| % Clasif. correctas por clase | |||||||
| Cluster 1 | 0 |
100 |
100 |
100 |
100 |
100 |
100 |
| Cluster 2 | 0 |
0 |
0 |
0 |
0 |
0 |
0 |
| Cluster 3 | 0 |
0 |
50 |
0 |
0 |
25 |
0 |
| Cluster 4 | 91.7 |
55.56 |
66.7 |
63.9 |
61.1 |
41.67 |
75 |
| Cluster 5 | 0 |
100 |
0 |
0 |
100 |
100 |
0 |
| % Clasif. correctas global | |||||||
| 76.74 |
51.16 |
62.8 |
55.81 |
55.81 |
41.86 |
65.12 |
|
MLP1_1 |
MLP2_2 |
MLP3_3 |
MLP4_4 |
MLP5_5 |
MLP6_6 |
MLP7_7 |
|
| % Clasif. correctas por clase | |||||||
| Cluster 1 | 0 |
0 |
0 |
0 |
0 |
100 |
0 |
| Cluster 2 | 0 |
20 |
0 |
0 |
40 |
40 |
60 |
| Cluster 3 | 9.1 |
81.82 |
45.45 |
72.72 |
72.72 |
36.36 |
81.81 |
| Cluster 4 | 100 |
97.9 |
100 |
96.84 |
100 |
97.9 |
98.95 |
| Cluster 5 | 0 |
75 |
50 |
75 |
75 |
100 |
100 |
| % Clasif. correctas global | |||||||
| 82.76 |
91.38 |
96.23 |
88.8 |
93.1 |
89.66 |
94.83 |
|
|
Tabla 1. Comparación
del desempeño en la clasificación para ambos grupos
de redes. |
Las matrices de confusión de ambas redes representan la calidad de la clasificación obtenida en la fase de test sobre cada clase en particular y la mejor calidad global de clasificación, como se muestra en las tablas 2 y 3.
|
MLP7 |
1 |
2 |
3 |
4 |
5 |
Total |
%
precisión en la clasificación |
|
1 |
1 |
0 |
0 |
2 |
0 |
3 |
33.33 |
|
2 |
0 |
0 |
0 |
3 |
0 |
3 |
0 |
|
3 |
0 |
0 |
0 |
4 |
0 |
4 |
0 |
|
4 |
0 |
1 |
4 |
27 |
1 |
33 |
81.82 |
|
5 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Total |
1 |
1 |
4 |
36 |
1 |
28/43 |
- |
|
% precisión
en la clase |
100 |
0 |
0 |
75 |
0 |
- |
65.12 |
Tabla 2. Matriz
de confusión de MLP7. |
|
MLP_7 |
1 |
2 |
3 |
4 |
5 |
Total |
% precisión
en la clasificación |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
2 |
0 |
3 |
0 |
0 |
0 |
3 |
100 |
|
3 |
0 |
1 |
9 |
1 |
0 |
11 |
81.81 |
|
4 |
1 |
1 |
2 |
94 |
0 |
98 |
95.92 |
|
5 |
0 |
0 |
0 |
0 |
4 |
4 |
100 |
|
Total |
1 |
5 |
11 |
95 |
4 |
110/116 |
- |
|
% precisión
en la clase |
0 |
60 |
81.81 |
98.95 |
100 |
- |
94.83 |
Tabla 3. Matriz
de confusión de MLP_7. |
La clase con mayor presencia en los datos de entrenamiento es cluster 4 (81%) seguido de cluster 3 (9%) cluster 2 (5%), cluster 5 (4%) y cluster 1 (1%). Esta distribución de las dominancias de unas clases sobre otras permite explicar los resultados arrojados en las matrices de confusión. Es interesante notar que este patrón se conservó con pequeñas variaciones en los datos arrojados en la fase de recall, lo que confirma la calidad de clasificación mostrada en la fase de test.
Con respecto a las curvas de aprendizaje el análisis se baso en el error cuadrático medio de entrenamiento, como se muestra en la figura 3.
Podemos observar en la figura que MLP7 se encontró entre las redes con una mejor calidad de aprendizaje. Este patrón de comportamiento tuvo características similares en el otro grupo de redes. Podemos comparar las curvas de aprendizaje de las redes MLP7 y MLP7_7.
Las curvas de aprendizaje de ambas redes confirman que prácticamente se produjo la misma calidad de aprendizaje en las dos redes. Las redes comienzan a tener una convergencia a partir de la época 3000. (una época es una presentación de grupo de datos de test a la red).
6. CONCLUSIONES
Las características de la muestra inicial que se utiliza en un experimento de esta naturaleza deben ser representativas de la realidad de los datos en el sentido de reflejar la dominancia de unas clases sobre otras. Esta relación entre las clases debe ser recreada en lo posible, tanto en la muestra de entrenamiento como en la muestra de test.
También es importante considerar que la muestra debe incluir distintas perspectivas de la realidad que se traducen en la inclusión de variables que consideren distintos dominios de la realidad. En este caso nos encontramos con dos grupos: variables descriptivas de terreno obtenidas directamente de la base cartográfica (pendiente, altitud y exposición) y variables provenientes de censores remotos (bandas o canales satelitales). Lo anterior permite ilustrar el hecho de que la minería de datos debe realizarse sobre muestras que permitan vincular variables con los orígenes más diversos para aumentar la cantidad y la calidad de información que se encuentra implícita en los datos.
Se considera que la calidad de la clasificación obtenida por la red real (65%) es aceptable, dadas las dificultades que presenta la muestra, producto de una desigual presencia de los individuos por clases. Por lo anterior se hizo necesario repetir el experimento con todos los datos (grupo MLPx_x).
Se considera una buena práctica experimentar con diversas configuraciones paramétricas haciendo variaciones sucesivas sobre grupos de parámetros de arquitectura y aprendizaje, escogiendo aquella que presente la mejor relación entre la calidad de aprendizaje y calidad en la clasificación.
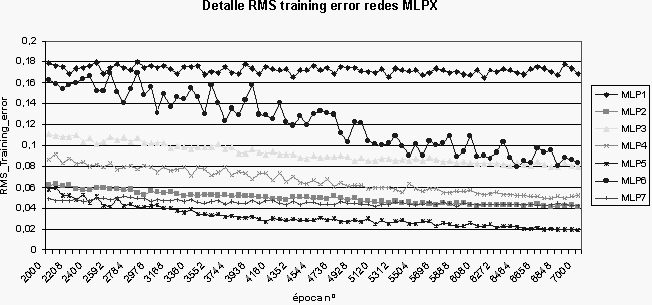 |
Figura 3. Comparación
de las curvas de RMS error. |
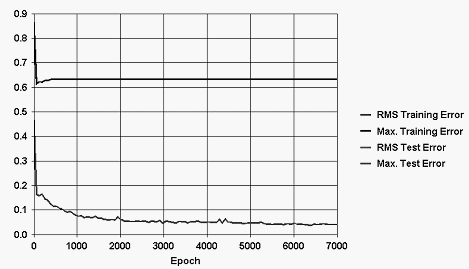 |
Figura 4. Curva
de aprendizaje de MLP7. |
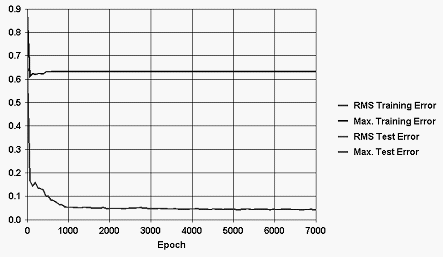 |
Figura 5. Curva
de aprendizaje de MLP7_7. |
REFERENCIAS
[1] INFOR, Desarrollo y aplicación de alternativas de manejo para el abastecimiento continuo de bienes y servicios con bosques nativos, FDI-CORFO/INFOR. Capítulos III y IV, 2002.
[2] Fallad M. U., Advances in Knowledge discovery and Data Mining,1996.
[3] Weber R, Data Mining en la Empresa y las Finanzas utilizando tecnologías inteligentes. Revista de Ingeniería de Sistemas, Volumen XIV, número 1. pp 61-78, 2000.
[4] Ruiz-Tagle Molina Camilo José, Aplicación de Data Mining sobre un SIG de caracterización forestal, Tesis para optar al título de Ingeniero Civil en Informática, 2003.
[5] Aykin Simon, Neural Networks a comprehensive Foundation, 1999.