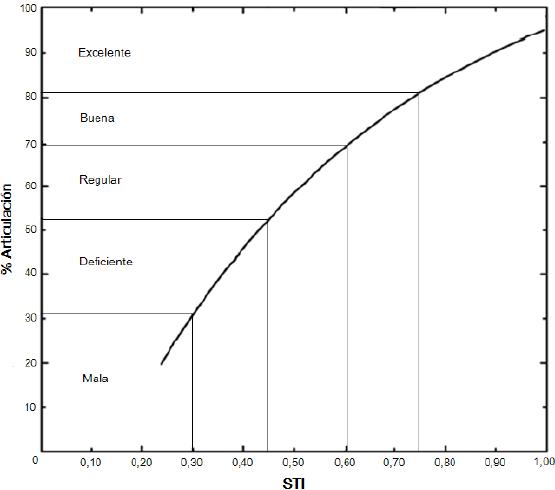
Figura 1: Relación
entre prueba subjetiva de logatomos CVC inglés y STI (ISO 9921)
[3].
Síntesis
Tecnológica. V.4 Nº 2 (2011) 37-49
DOI:10.4206/sint.tecnol.2011.v4n2-06
Elaboración de un corpus de logatomos fonéticamente balanceados para la evaluación de la inteligibilidad de la palabra en español1
Elaboration of a phonetically balanced corpus logatomos for evaluation of speech intelligibility in Spanish
Juan Hidalgo 1, Jorge Sommerhoff 2, Claudia Rosas 3
1 Universidad
Austral de Chile, Valdivia, Chile. Ingeniero Civil Acústico. E-mail:
juananh@gmail.com.
2 Universidad Austral de Chile, Instituto de Acústica.
E-mail: jsommerh@uach.cl.
3 Universidad Austral de Chile, Instituto de Lingüística
y Literatura. E-mail: claudiarosas@uach.cl.
1 Este trabajo
ha sido desarrollado bajo el marco del proyecto FONDECYT Regular 1090249 financiado
por CONICYT, cuyo director es el Dr. Jorge Sommerhoff Hyde, profesor del Instituto
de Acústica de la Universidad Austral de Chile.
RESUMEN
El presente trabajo elabora y evalúa un listado de logatomos fonéticamente balanceados para medir la inteligibilidad de la palabra en español. El listado original considera todas las combinaciones de sonidos CVC (logatomos de la forma consonante + vocal + consonante), excepto en las neutralizaciones, donde se considera solo una combinación tipo. Para la evaluación se aplicó un test de articulación mediante audífonos a 10 estudiantes universitarios. Los resultados evidenciaron un promedio de 97,70% de logatomos correctamente transcritos y un 2,30% de logatomos con errores en la transcripción, con un 1,51% en la primera consonante, un 0,61% en la segunda consonante y un 0,18% en la vocal. Un análisis más detallado reveló que la mayoría de errores recurrentes se concentraron en las consonantes iniciales, vibrante múltiple /rr/ y nasal palatal /ñ/, y en la consonante final palatal lateral /ll/. Este balance justificó la elaboración de un nuevo listado integrado por 750 logatomos.
Palabras clave: audición, comunicación, habla, inteligibilidad, logatomos.
ABSTRACT
This study elaborates and evaluates a list of phonetically balanced logatoms to measure the speech intelligibility on Spanish language. The original list considers all the CVC sound combinations (logatoms of the form consonant + vowel + consonant), except in the neutralizations, where it is considered only one standard combination. For the evaluation, an articulation test was applied to ten university students through headphones. The results showed a 97,70% average of correctly transcribed logatoms and a 2,30% of logatoms with transcription errors, with a 1,51% on the first consonant, a 0,61% on the second one and a 0,18% on the vowel. A more detailed analysis revealed that the higher recurrent errors concentrate on the initial consonants, multiple vibrant /rr/ and the lateral palatal /ll/, and the final consonant nasal palatal /ñ/. This balance justified the elaboration of a new listing composed by 750 logatoms.
Key Words: Audition, communication, speech, intelligibility, logatoms.
1. INTRODUCCIÓN
Son muchas las consecuencias sociales que se derivan de no oír correctamente los sonidos que se articulan con fines comunicativos, especialmente dentro de establecimientos públicos de enseñanza, tales como fatiga, irritabilidad y desconcentración, producto del mayor esfuerzo mental invertido debido a la confusión de sonidos, además de la propia interpretación incorrecta del mensaje. Por lo tanto, es de suma importancia contar con salas que permitan una comunicación efectiva para evitar efectos no deseados.
El parámetro acústico más importante para definir la calidad acústica de un local diseñado para la comunicación hablada es la inteligibilidad. Se define inteligibilidad del habla como una medición de la capacidad de comprensión del material lingüístico articulado [1]. Para evaluar la inteligibilidad existen procedimientos objetivos y subjetivos. Los objetivos utilizan aparatos electrónicos para realizar mediciones, cuyos resultados se correlacionan con los entregados por los métodos subjetivos (figura 1 y tabla 1). El más importante de los métodos objetivos es el STI (Speech Transmition Index), desarrollado por Houtgast y Steeneken [2]. A su vez, los procedimientos subjetivos utilizan personas que realizan pruebas de articulación, que miden la cantidad de sílabas, palabras o frases que alguien escribe correctamente al oírlas. Si bien este tipo de métodos es más exacto y fiable, presentan la desventaja práctica de contar con un listado adecuado de estructuras silábicas y de personas preparadas para su locución y audición.
|
Figura 1: Relación
entre prueba subjetiva de logatomos CVC inglés y STI (ISO 9921)
[3]. |
 |
Tabla 1: Rangos
de clasificación de inteligibilidad y STI, según norma ISO
9921 [3]. |
Existen varios estudios previos que han desarrollado pruebas con diversos métodos subjetivos de articulación. James Egan, en 1943, utilizó listados de palabras monosílabas fonéticamente balanceadas comunes para el inglés [4]. Para el español existen dos listas de estructuras silábicas, una publicada por Fuchs y Osuna [5] y otra, por Miñana [6]. Estas listas ya han sido estudiadas por Sommerhoff y Rosas [7] y también han elaborado y evaluado varios listados de logatomos para medir la inteligibilidad de la palabra en español [8]. Aún así, los progresos realizados en países de habla hispana están aún distantes de alcanzar a los de habla inglesa, donde EE.UU. es gestor de un vasto desarrollo, el cual le ha permitido poseer validación y certificación internacional en la materia desde hace décadas [9].
El objetivo de este estudio es conformar un corpus de logatomos que sea fonéticamente balanceado; es decir, que los fonemas que lo compongan aparezcan en la misma proporción (carácter cuantitativo) y sean estructuralmente representativos con respecto al español hispanoamericano. Además este corpus debe garantizar que arrojará valores muy cercanos al 100% de inteligibilidad cuando sea evaluado en ausencia de la acústica de un recinto, principalmente ruido de fondo y reverberación. Para ello se aplicó un test de articulación a 10 informantes universitarios, que mediante audífonos escucharon el listado de logatomos y transcribieron los segmentos para su posterior revisión y análisis.
2. MARCO TEÓRICO
Se analizó en estudios previos el comportamiento de los logatomos CVC [8] y se concluyó la importancia de las consonantes en el porcentaje de error [10].
Este listado experimental está formado por logatomos CVC que considera 21 fonemas del español hispanoamericano y todas las combinaciones posibles, excepto en los casos que ocurre neutralización, donde se ha optado por considerar sólo uno de los sonidos que forma la oposición [11]. La neutralización ocurre cuando una oposición deja de ser significativa en una posición de la cadena hablada, como /r/ (vibrante simple) y /rr/ (vibrante múltiple) en posición final de sílaba. De esta forma, al pronunciar "marte" con /r/ o /rr/ no afecta el significado. Este hecho se denomina técnicamente distribución efectiva. La articulación de los logatomos debe ser realizada según la pauta que rige la interpretación para el español hispanoamericano. Para la representación gráfica se ha utilizado el sistema ortográfico español.
Por supuesto que se ha tenido en cuenta el hecho de que la mayoría de los fonemas que integran los logatomos CVC de este listado, en una posición determinada, no aparezcan nunca (como la /r/ en la posición inicial o explosiva) o rara vez, como casi todas las demás consonantes en posición final o implosiva [11]. De la tabla 2.1 se observa que la estructura que tiene mayor frecuencia (con respecto a la cantidad de palabras que se pueden generar) en el idioma español es la estructura CV, pero se ha determinado considerar una estructura con una mayor proporción de consonantes, ya que estas entregan mayor cantidad de información con respecto a las vocales. Por lo tanto, se determina que la estructura a utilizar será la CVC, que es la segunda en porcentaje de frecuencia.
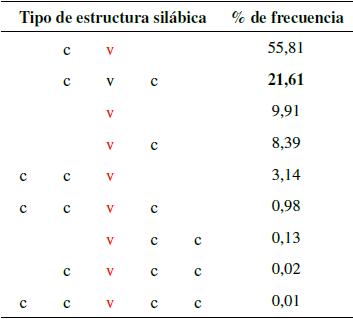 |
Tabla 2: Estructuras
silábicas del español ordenadas según su porcentaje
de frecuencia [11]. |
A continuación las consideraciones para las consonantes de la estructura CVC.
Elisión de la primera consonante (CVC):
• "c" porque se articula
como "k".
• "h" porque no se articula (muda).
• "q" porque se articula como "k".
• "x" porque se articula como "j".
• "v" porque se articula como "b"
(variante gráfica).
• "y" porque se articula como "ll".
• "z" porque se articula como "s".
Elisión de la segunda consonante (CVC):
• Todos los casos donde
ocurre neutralización: "b" por "p"; "d" por "t"; "g" por "k", "c" y "q";
"n" por "m".
• "h" porque no se articula (muda).
• "ñ", debido a que no existen
palabras terminadas con esta consonante.
• "v" porque se articula como "b"
(variante gráfica).
• "w" porque se articula como "b"
o "g".
• "x" porque se articula como una
combinación de dos consonantes ("cs", "ks").
• "y" porque se articula como "ll".
• "z" porque se articula como "s".
3. METODOLOGÍA
3.1. SELECCIÓN DE INFORMANTES
El listado de logatomos fue evaluado por 10 informantes, los cuales fueron seleccionadas de acuerdo a dos requisitos: el primero de ellos es que posean capacidad ontológica normal. En general, no deben poseer pérdidas auditivas mayores a 15 dB en ninguna banda de frecuencia entre 500 y 8KHz, lo que se verificó mediante audiometrías de tono continuo. Un ejemplo de un resultado favorable se aprecia en la figura 2:
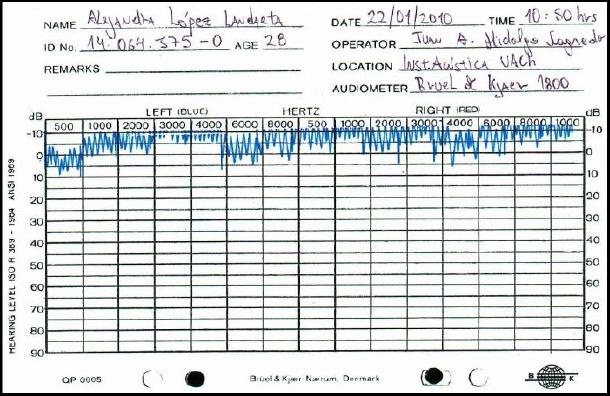 |
Figura 2: Hoja
resultados audiometría de tono continuo. |
El segundo requisito, es que asimilen debidamente las instrucciones para la administración del test, que consiste en enseñar el contenido de las listas (lectura en voz alta por parte de un locutor y de ellos mismos) y una tabla que especifica las grafías a utilizar para representar los fonemas (tabla 3):
 |
Tabla 3: Sistema
de ayuda para la transcripción de logatomos. |
3.2. PROCESO DE GRABACIÓN DE LOGATOMOS
Este proceso fue realizado en una cámara anecoica de la Universidad Austral de Chile con el fin de evitar interferencias en la señal original, ya que se simula la condición acústica de campo libre, siendo prácticamente nula la energía reverberante. La grabadora se configuró en canal mono, y para la digitalización un sampleo de 96KHz y resolución de 24bits, en formato WAV. La cadena electroacústica se estableció como muestra la figura 3:
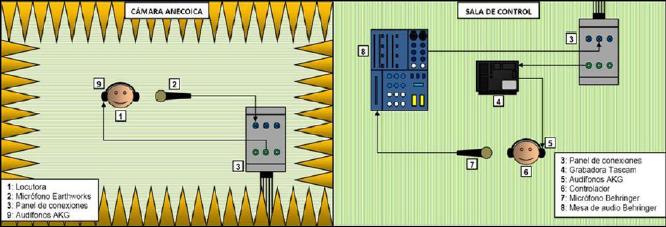 |
Figura 3: Cadena
electroacústica del proceso de grabación. |
Los logatomos de la tabla 4 fueron leídos por un miembro del equipo de trabajo, con competencias en fonética para articularlos correctamente. Estos fueron divididos en dos listas, según su grado de dificultad articulatoria (las celdas de color amarillo indican menor dificultad articulatoria, y las verdes mayor dificultad.).
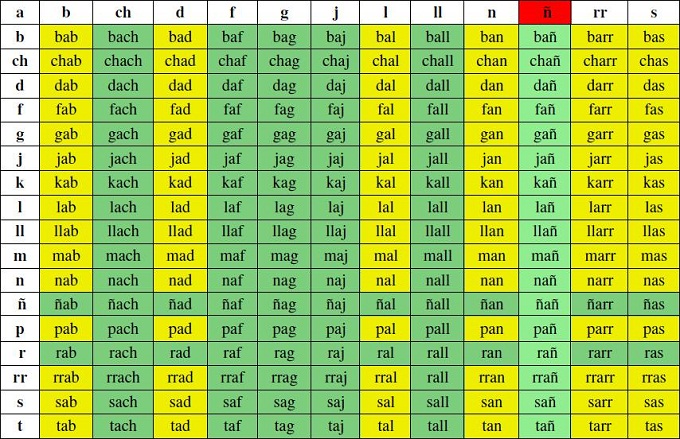 |
Tabla 4: Matriz
de logatomos (con respecto a la vocal "a"). |
Los logatomos fueron leídos con una separación de 2 a 3 segundos para así evitar ruidos glotales, ya que si se deja demasiado tiempo entre cada emisión las cuerdas vocales se relajan, produciendo mayor ruido al volver a tensarse. La distancia entre el micrófono y la boca del locutor es de 15 centímetros, ya que los niveles de ganancia de la grabadora fueron ajustados con el nivel de presión sonora producido a esa distancia. Una distancia menor puede producir un aumento de la intensidad en bajas frecuencias. Una vez realizadas todas las sesiones se procedió a audicionar los logatomos, con el fin de determinar errores en la articulación y evaluar posteriores cambios. Se encontraron anomalías en la articulación y en la percepción, producto de la dificultad intrínseca de algunos segmentos y de efectos articulatorios menores. Por este motivo se eliminaron a priori los logatomos con la consonante "ñ" en posición final o implosiva (celda en color rojo).
3.3. PROCESO DE EDICIÓN Y CONSTITUCIÓN DEL LISTADO DEFINITIVO
Luego de la revisión de las grabaciones se procedió a editarlas, considerando los siguientes procesos: I. Separación de logatomos, determinando los "endpoints" de cada uno. II. Reemplazo los logatomos que presentaban anomalías circunstanciales. III. Normalización. IV. Creación de sublistas con distribución aleatoria de logatomos, con separación de 2 segundos entre si. V. Compresión de audio (16bits/44.1KHz). Se constituyó entonces un listado final de 935 logatomos divididos en 11 sublistas de 85 logatomos cada una, aleatoriamente distribuidos, más una frase introductoria al comienzo. Cada sublista tiene una duración aproximada de 3 minutos y 50 segundos, siendo el tiempo total estimado del listado 42 minutos y 10 segundos.
3.4. ADMINISTRACIÓN DE LOS TESTS DE INTELIGIBILIDAD
Los informantes realizaron 3 pruebas de articulación del listado, considerando como definitiva la tercera. Estas fueron realizadas en un recinto que poseía bajo nivel de ruido de fondo (menor a 40 dBA) y mediante audífonos, para garantizar que no hubiese problemas de inteligibilidad por factores externos (como es el ruido de fondo y la reverberación, principalmente). Se asume que esta condición corresponde a un 100% de inteligibilidad. Los informantes transcribían las audiciones en una ficha especial para tal efecto.
4. RESULTADOS Y DISCUSIÓN
Tras la aplicación de las 10 pruebas finales de articulación, se obtuvo un promedio de inteligibilidad, para un total de 9350 logatomos, de 97,70%. Ese porcentaje corresponde a un total de 9150 logatomos escuchados correctamente, de los cuales 158 tienen cambios en la transcripción. Los logatomos con error, en algún grado, corresponden a 215 (2,30%). A continuación se muestra en la Tabla 5, el resumen de la recurrencia del error en la estructura CVC.
 |
Tabla 5: Resumen
de recurrencia total del error en la estructura CVC. |
Un análisis más detallado de estos logatomos muestra cuales son las consonantes y vocales, en su respectiva posición en la estructura CVC, que poseen mayor frecuencia de error (tablas 6, 7 y 8):
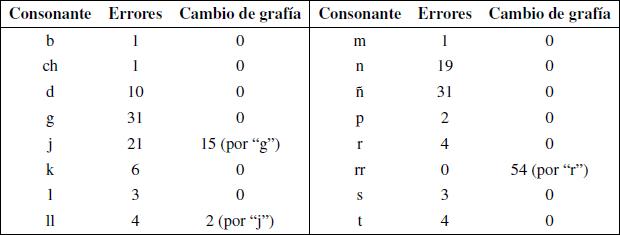 |
Tabla 6: Resumen
de frecuencia de error en la primera consonante. |
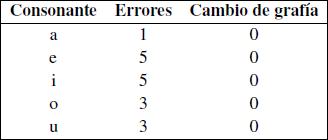 |
Tabla 7: Resumen
de frecuencia de error en la vocal. |
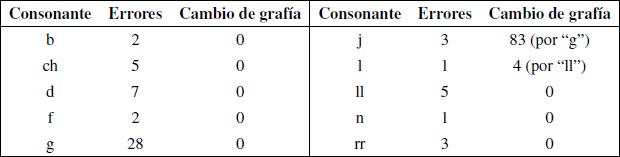 |
Tabla 8: Resumen
de frecuencia de error en la segunda consonante. |
De la tabla 5 se observa que casi el total de los errores se producen en las consonantes, siendo la posición explosiva (inicial de la sílaba) la que posee mayor recurrencia.
Una de las partes de mayor cuidado fue la obtención de los resultados específicos en la estructura CVC, dado que hubo que consensuar en cada caso que se entendería por error auditivo real, distinguiéndolo del error por concepto gráfico. En general, se les pidió a los informantes su opinión y comentarios al término de las pruebas, para tener mayor discernimiento al momento de adoptar las consideraciones que vienen a continuación. De las tablas 6 y 8, para el caso del fonema /j/, se aprecia que la mayoría de los errores corresponden a interpretaciones mediante la grafía "g", siendo 98 casos de un total de 122 errores para /j/. De esta forma, es poco probable que realmente se haya tenido un problema de inteligibilidad en esos 98 casos, ya que existen palabras en español en que la grafía "g" se interpreta como el fonema /j/. Por esta razón, se asume que los informantes asociaron esta relación y por lo tanto son considerados como cambios en la grafía en vez de logatomos con error. Para el caso del fonema /ñ/, de los 31 errores, 25 son interpretados mediante la grafía "n" y 6 mediante la grafía "m". Si bien en este caso no existe neutralización entre lo articulado y sus representaciones, existe un tipo de asociación, por el hecho que los errores se deban sólo a dos grafías mencionadas. Para el caso del fonema /rr/ de los 54 errores, 54 se representaron mediante la grafía "r". En este caso se asumen estos errores como cambios en la grafía, ya que se produce neutralización entre estos dos fonemas; además, no existen palabras en español que comiencen con el fonema /r/ (vibrante simple). El otro caso interesante fue del fonema /ll/, ya que de sus 5 errores, 5 fueron interpretados mediante la grafía "ch", y de los 5 errores del fonema /ch/, 4 fueron interpretados mediante la grafía "ll". Esto habla de una confusión entre las dos consonantes, ya que de los 10 errores, 9 fueron recurrentes entre ellas. También se aprecian 4 cambios en la transcripción del fonema /l/, interpretado por "ll". Se cree que estos cambios son asociaciones con respecto al idioma inglés. En el resto de las consonantes, en posición inicial y final, los errores no presentaron una tendencia marcada o reiterativa con respecto a algún otro fonema en particular, y no hubo más casos en que se considerara una relación con otras grafías [12]. De la información de la tabla 7, se asume que estos errores son debido a distracciones, ya que entre las vocales no se producen neutralizaciones y difícilmente algún tipo de asociación.
Los resultados obtenidos presentan diferencias que se pueden deber a aspectos propios de cada informante: su estado de ánimo, la predisposición al momento de realizar un test y nivel de cansancio durante la evaluación, etc. Al tratarse de estímulos verbales los que producen la tarea cognitiva de transcripción, se activa en el cerebro una estructura de memoria auditiva a corto plazo llamada "registro sensorial", que se caracteriza por almacenar gran cantidad de información pero por muy poco tiempo. A su vez, el sistema central de control atencional es el encargado de regular la conservación de la información auditiva y se relaciona además con el tratamiento y comprensión del lenguaje oral [13]. Al ser los logatomos estructuras silábicas sin significado, no se produce una representación semántica por parte del individuo, lo que evita asociaciones que pudiesen producir errores en la transcripción; es decir, no existe una imagen mental para los segmentos, pudiendo existir excepciones, como en "jill" (gil), "jen" (gen), "llas" (jazz), cuyos sonidos evocan significados del español, o del inglés en "llob" (job), "llar" (jar), "pul" (pull). Dejando estos casos de lado, en definitiva, las alteraciones en la percepción por parte de los auditores se producen fundamentalmente por factores internos del individuo y/o circunstancias externas del ambiente que le rodean [14], [15]. Sobre lo mismo, se afirma que el entrenamiento puede afectar positivamente el desarrollo del test, si bien, no se sabe a priori en que grado.
5. CONCLUSIONES
Con respecto a la aplicación de los test de articulación efectuada con logatomos de estructura CVC, en condiciones de 100% de inteligibilidad, se obtuvo un porcentaje de error de 2,30. Este error se debe principalmente al uso de composiciones CVC que causaron confusión en su percepción. Por lo tanto, los resultados que se obtienen de este tipo de medición subjetiva dependen, aparte del tipo de estructura silábica, de las limitantes lingüísticas producidas por las combinaciones CVC utilizadas. Se concluye además que el proceso de edición de las respuestas debe ser general, pero flexible para tratar algunos casos particulares de ambigüedad.
Con respecto a los análisis previos, se realizaron las siguientes modificaciones en el listado:
• Eliminación de
la consonante "r", ya que en posición explosiva (inicial de la palabra)
se produce neutralización entre los fonemas /r/ y /rr/.
• Eliminación de la consonante
"ñ" en posición explosiva, ya que produjo confusión recurrente
con el fonema /n/.
• Eliminación de la consonante
"ll", en posición implosiva (final de la palabra), ya que produjo confusión
recurrente con el fonema /ch/, y viceversa.
Finalmente el corpus definitivo se constituyó con 750 logatomos fonéticamente balanceados (tabla 9):
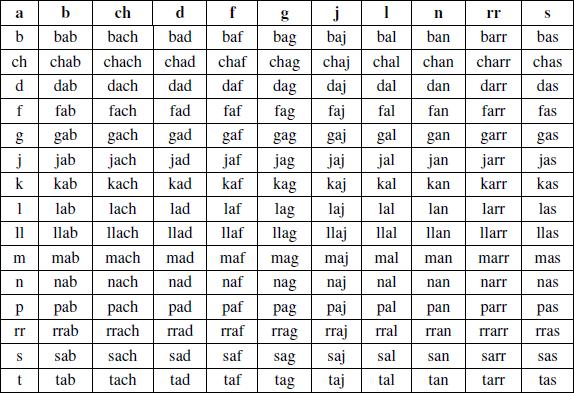 |
| Tabla 9: Corpus definitivo de 750 logatomos (con respecto a la vocal a). |
6. REFERENCIAS
[1] Llisterri, J. (1991). Introducción a la fonética: el método experimental. Barcelona: Editorial Anthropos.
[2] Houtgast, T., y Steeneken, J., M. The modulation transfer function in a room acoustics as a predictor of speech intelligibility. Acustica 28, 1, 66-73 (1973).
[3] International Standard Organization. Ergonomics-Assessment of speech communication. ISO 9921:2003.
[4] Egan, F.P., Articulation testing methods. Laryngoscope (1948).
[5] Fuchs, G., L., y Osuna, J. Medición de inteligibilidad. Memoria de las Primeras Jornadas Latinoamericanas de Acústica. Universidad Nacional de Córdoba, Argentina (1965).
[6] Miñana, P. Compendio práctico de acústica. Barcelona: Labor (1969).
[7] Sommerhoff, J., Rosas, C. Evaluación de la inteligibilidad del habla en español. Estudios Filológicos 42 (2007).
[8] Rosas, C., Sommerhoff, J., Inteligibilidad acústica en español: una propuesta para su medición. Estudios Filológicos 43 (2008).
[9] ANSI Standard S3.2-1989. Method for measuring the intelligibility of speech over communication Systems. New York.
[10] Sommerhoff, J., Rosas, C. Listas de logatomos en español fonéticamente balanceadas y correlacionadas con STI para medir la inteligibilidad del habla. IV Congreso de Fonética Experimental, Granada (2008).
[11] Quilis, A. (1999). Tratado de fonología y fonética españolas. Madrid: Gredos.
[12] Hidalgo, J. (2011). Elaboración de un corpus de logatomos fonéticamente balanceados para la evaluación de la inteligibilidad de la palabra en español. Tesis de Pregrado, Facultad de Ciencias de la Ingeniería, Universidad Austral de Chile, Valdivia.
[13] Baddeley, A. D., Hitch, G. (1974). Advances on Learning and Motivation. Working memory. New York: Academic press.
[14] Godden, D., Baddeley, A. D. (1980). When does context influence recognition memory?. British Journal of Psychology.
[15] Smith, S. M., Glenberg, A., Bjork, R. A. (1978). Environmental context and human memory. Memory & Cognition.